
How do we control AI agents?
The hard problem of agents
We believe that to make agents work at scale, we’re going to need entirely new evaluation methods, interfaces, and oversight mechanisms. To deploy reliable, safe and continuously improving agents we’ll need:
- Evaluations that build themselves
- Runtime agent supervision that is scalable to millions of agents
- Seamless human-agent interaction that allows for fast, intuitive and context-aware oversight
There isn’t a great existing solution for this, so we’re building it. It’s called Asteroid, and you can join our beta here.
Agents as a new category of software
LLM-backed agents represent an entirely new category of software. By integrating LLMs into our systems, we can hand off runtime decision-making authority to AI agents that behave competently in the face of uncertainty. This is a powerful paradigm shift, which is enabling applications that were previously impossible:
- Autonomous software engineers that can write code, debug and deploy to production
- Customer support agents that can resolve complex customer issues autonomously
- Research assistants that can aid in critical decision making
but these new applications also bring with them several unsolved problems:
- What sort of decisions can your software make on your behalf?
- How should human operators supervise these agents in a scalable way?
- How do you evaluate success rates of increasingly general-purpose software systems?
These fundamental questions pose significant challenges, and we’re very much in the early days of defining these problem statements and venturing towards solutions. If we get them right, we have good reason to believe that extraordinary potential lies ahead.
Agent development is wildly inefficient
Today, many companies deploying agents go through the same life cycle:
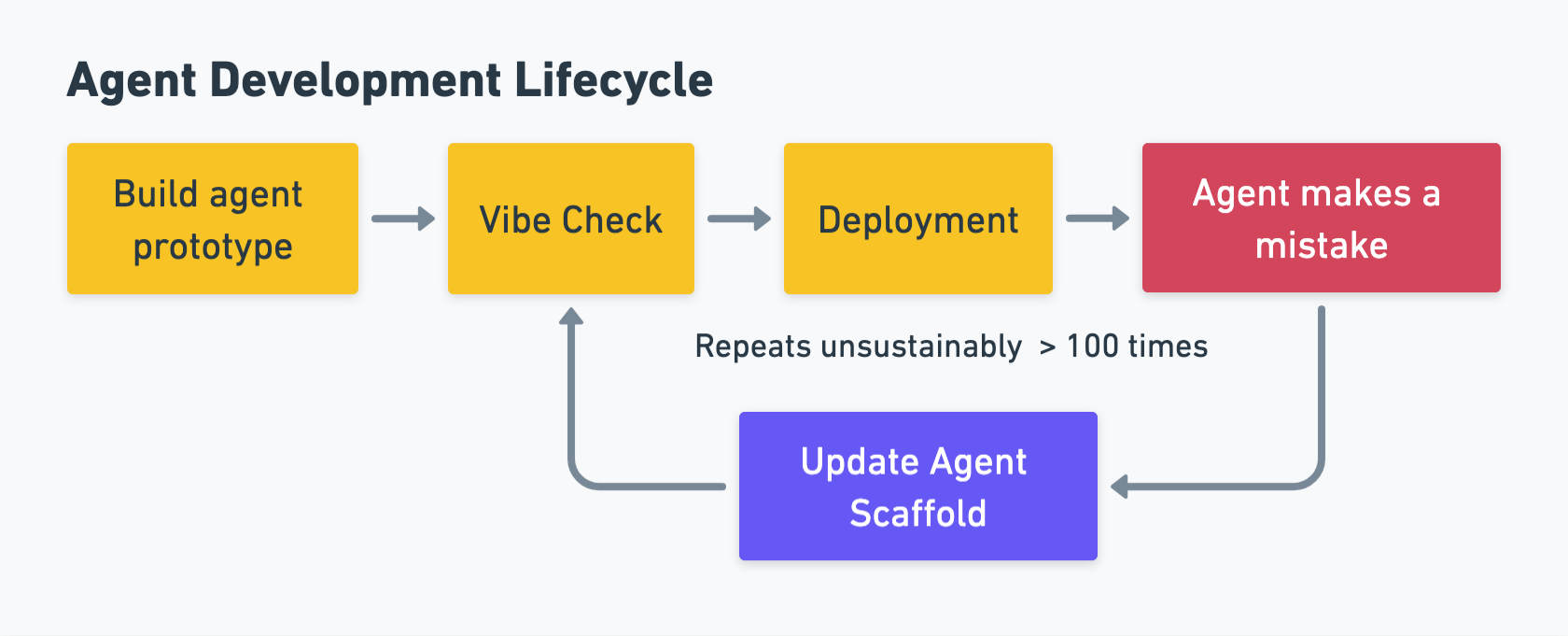
In this world, it is frequently the case that developers do not know whether code changes they are making are actually working until the system has been deployed, and they might not uncover newly introduced issues until a customer reports them.
This agent development lifecycle makes the development loop slow and frustrating.
Evals are a partial solution
Traditional evaluation approaches, like those used for machine learning models, involve creating test sets to measure model performance offline. In theory, these tests would allow us to iteratively improve agents by modifying their scaffolding, prompts and underlying models. If our offline tests map well to runtime scenarios, we should be able to predict how the agent will perform in production.
But as well as being slow and labor-intensive, building comprehensive test sets for agents is extremely difficult. While it’s straightforward to create test cases for simple classification tasks (like ID verification where the model just needs to output “accept” or “reject”), agents can take complex sequences of actions that are hard to anticipate and validate.
The impact of individual actions is hard to evaluate. When an agent executes an action (like running a bash command or modifying code), it’s difficult to assess:
- How this action will affect the environment and future states
- Whether this action increases or decreases the probability of task success
- What potential failure modes or side effects might occur
- The impact of this action on the world, and the potential consequences of failure
It appears that traditional LLM evaluations are insufficient for the agent paradigm, so what’s next?
The future of agent development
The following is a rough sketch of what we believe a good solution to agent supervision and evaluation would look like. Some of these features are available today with Asteroid, and we’re actively working on the rest.

Asteroid Beta
To address the above challenges, we are launching the closed beta for Asteroid, a powerful new way to improve agent reliability and safety.
Asteroid makes it much easier to rapidly prototype, evaluate and monitor agents in the wild. In just a few lines of code, you can add Supervisors to your agent which can catch unintended behaviors and edge cases.
Asteroid is not an agent framework. It can hook into any agent of your choice and instantly give you runtime safety and reliability guarantees. Hooking into an agent is as simple as adding a decorator to your function:
from asteroid import supervise, LLMSupervisor, HumanInTheLoopSupervisor
@supervise(
supervisors=[
LLMSupervisor(prompt="You are a helpful assistant"),
HumanInTheLoopSupervisor()
]
)
def my_function():
return "Hello, world!"
Asteroid is a Python package and a user interface that you can install and run locally using Docker. The UI gives you deep insights into agent actions, tools that the agent is using, and how supervisors have responded to requests by your agent to execute those tools.
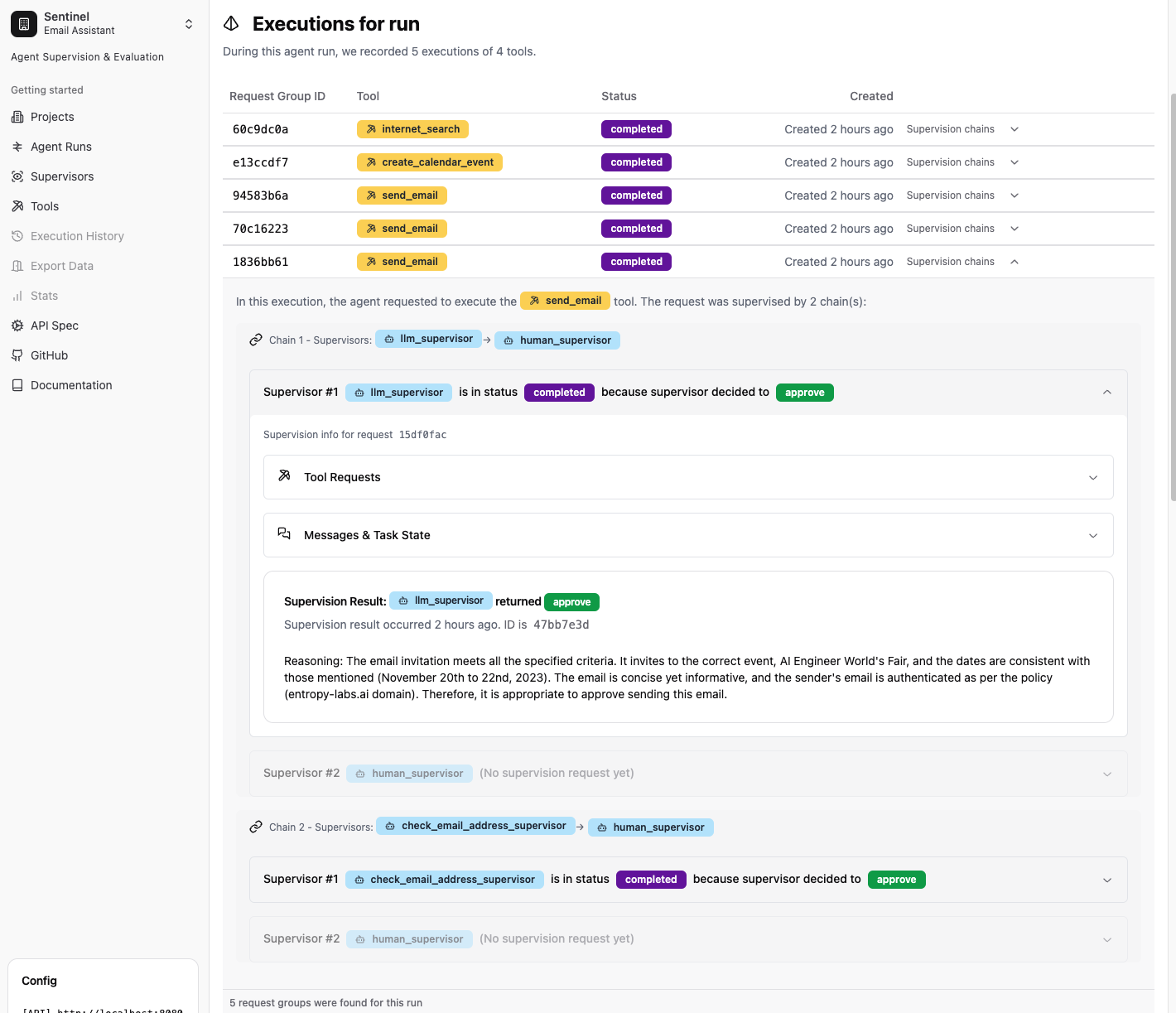
The UI allows human operators to manually approve, reject or modify agent tool requests. A common design pattern is to have automated supervisors run first and only escalate to human when problematic behavior is detected.
The main functionalities that Asteroid provides:
- Customizable supervisors for any tool call
- Human in the Loop
- Tool stubbing for deterministic evaluation of agents
Supervisors
A supervisor is a function that returns a decision when given some information about the agent and its desired action. In the AI Control ontology, these are called ‘Monitors’.
Developers can use our Python decorator to attach a list of supervisors to any function that that is available to your LLM.
How do Supervisors work?
When your agent decides to call a function, before the function call is executed, the supervisors attached to the function will check whether the execution can proceed and return a decision which determines what happens next:
approved:the tool is executedreject: the tool is not executed the agent must retryescalate: the decision is deferred to the next Supervisor in the chainmodify: the action is accepted, with modifications
Supervisors enable us to catch unintended agent behaviors at runtime, and very often allow the agent to correct its own actions. Supervisors are very simple, and highly configurable, making them a very powerful tool for quickly enforcing policies and behaviors onto an LLM-based system.
Out-of-the-box Supervisors
We provide a wide range of supervisors out-out-the-box, so you can get started supervising your agents immediately.
Configuring a new Supervisor for your use case
The configuration of a custom LLM Supervisor for example, could be as simple as passing a company policy document to an LLM and asking it whether the current agent’s trajectory is inline with the policy. The LLM can then return either approve, reject, modify, escalate or terminate to the agent. Supervisors implementation is extremely flexible. It can include another AI models or deterministic supervisors such as regex rules. We provide some common supervisors that can be configured out of the box, e.g. LLM supervisor, Bash commands supervisors, Python code execution supervisor. But Asteroid users can bring their own specialized supervisors tailored to the agent and provided tool calls.
Chaining Supervisors together
Supervisors can be chained together and run in parallel. For example fast deterministic supervisor can escalate to AI-based supervisor that can escalate to human. Developers can create multiple supervisor chains that can run in parallel, each checking for specific behavior.
Human in the Loop
Some agent actions might need human approval. For this, we provide a Human in the Loop Supervisor that works with our UI, giving you immediate human control.
The most basic usage of our Human in the Loop Supervisor is to add it directly to a tool with no other Supervisors. In this case, every execution of this tool will need human approval.
A more sophisticated use of the Human in the Loop Supervisor is to chain supervisors together, such that the human only steps in to approve actions when multiple automated supervisors did not pass.
The human operator is presented with all context needed to make a decision in the UI. This includes previous messages, tool calls, current tool call and arguments, and previous supervisors that escalated along with their reasoning. The human can approve, reject or modify the tool call to steer the agent on a correct trajectory.
Mocking
When evaluating LLM applications, it’s useful to be able to test the application without the risk of unintended side effects. Since our supervise() decorator wraps around the tool calls, it can also be used to stub the tool calls. This is useful when the tool call can have impact on your system (such as changing data in a database or writing files to disk)
Find out More
Go to our documentation for more detailed explanations and examples. You can learn more about how our supervisors work, how our human in the loop UI looks like and get instructions on how to start using Asteroid. Check out one of our examples for a customer support agent that uses our AI supervisors with human-in-the loop escalation for high risk-actions.
If you’d like to deploy agents quickly, reliably and safely with Asteroid, book a demo with us.
Schedule a Demo